谈谈事件循环(event-loop)
事件循环在前端圈子里,是一个经常被谈起的技术知识。互联网上也有很多关于事件循环的技术文章,有写的好的,也有很多都是为了蹭访问量的水文。总之,事件循环的确是一个难懂,需要反复理解并且稍加实践的抽象知识。光在脑子里靠抽象的去理解是不够的,如果能结合实际,写一个例子会更有助于我们理解。
前端工程师为什么需要了解事件循环,部分人纯粹就是为了应付面试,对还抱有这种想法的人,我认为最多是个初级前端工程师。如果你没有理解事件循环,你就无法知道:
- 为什么
Promise、MutationObserver、queueMicroTask等 api 的回调任务总是优先于setTimeout执行. - Vue 中的
nextTick这个 api 为什么可以让我们获取到最新的 DOM 并操作. - UI-Render 到底是在什么时候进行的.
要想好好讲清楚事件循环, 弄明白上面几个问题,就必须得先讲讲javascript中绕不开的几个概念知识。
call-stack
call-stack也称之为调用栈, 在 js 中所有的函数都会被放入这个栈中执行,call-stack遵循 LIFO 的特点。最先被放入到栈中的函数最后被执行,栈中存放每个函数的地方称之为frame,每个frame代表函数被调用一次。
TIP
当 js 引擎执行调用函数这个操作时,才会把该函数推入到call-stack中。请注意,并不是解析代码的时候 push,而是执行的时候 push。
function foo() {
baz();
}
function baz() {
bar();
}
function bar() {
//
}
foo();当 js 执行到上面高亮的一行代码foo(),会将 foo 推入到call中, 假设此时的栈是 empty 的,那么栈目前的情况通过可视化来描述就是.
可以看到执行foo,foo先被推入到栈中,,接着在foo()函数体内执行baz(),此时baz()也随之被推入到栈中,要注意的是,foo()仍未执行完噢,所以foo函数仍然在栈中。继续在baz()函数体内执行代码,遇到了bar()这行函数调用的代码,所以bar()也被推入到栈中。执行完bar()函数中所有的代码后bar()出栈,依次重复这样的操作,直到栈中所有的任务执行完毕,栈为空。
task
task 以前在被人总是叫做宏任务队列,我查阅了很多相关的资料。task 最准确的翻译是叫做任务队列,为什么我能得出这个结论?是因为我从 whatwg-event-loop 查阅了规范,规范明确定义了事件循环包含task queue 和 microtask queue.
而 task queue 的数据结构并不是一个 queue,而是set(一个存放所有的 task 的集合)
Task queues are sets, not queues, because the event loop processing model grabs the first runnable task from the chosen queue, instead of dequeuing the first task.
processing-model总是从task queue中取出第一个能运行的 task 并执行,而不是像队列一样采用 FIFO 那种方式取出任务。
我想强调的是什么叫做runnable task也就是可运行的task。
在浏览器环境中,除了setTimeout等api是一个task,对于Input Event也是一个task,例如我们给某个dom注册一个点击事件, 那么这个事件的回调会放入到task中。为什么task不是基于队列这一数据结构设计的?因为队列最大的特点是FIFO(先进先出)!如果注册的click-event回调放到一个队列的头部,紧接着放入一个setTimeout的回调。那么想要执行延时器的回调函数是不是得先出队。如果要出队,是不是得让click-event的task先出队。所以问题就来了,click-event如果非人为出触发的话,就被执行肯定非常不合理啊!所以我总算是明白了什么叫做runnable task. 以及为什么不是设计成队列的数据结构。而是一个set也称之为集合。
task queue中的任务总是优先于microtask queue执行,当执行一个 task 时,会将 task 内的所有的microTask放入到 microTask queue.
在浏览器运行环境中,像setTimeout、setInterval等这样的 api 执行的时候会将其回调函数 push 到 task queue中。等待 processing-model 取出并执行。
microTask
microTask 也称之为微任务, microTask 不等同于 task, 所有的microtask都会放入到microtask queue。根据规范定义,microTask queue是一个queue,而不是Set. 那么根据队列的特性,先进来的任务先会被执行并出队,直到队列为空。
Each event loop has a microtask queue, which is a queue of microtasks, initially empty. A microtask is a colloquial way of referring to a task that was created via the queue a microtask algorithm.
microTask-queue中的所有的 task 全部执行完毕后,当队列为空时,才会重新开始执行下一个 Task。注意,如果在浏览器环境下,当所有的 microTask 出队后,会触发一次 UI 的 Render, 也就是说当微任务队列为空后,浏览器渲染一次页面, 更新DOM树。
microtask相关的 api 有Promise、Mutation-Observer,queueMicroTaskeg...
事件循环的运行机制
为了更好的去了解事件循环,下面提供一个示例去了解事件循环的工作机制
<script>
const foo = "foo";
function printFoo() {
setTimeout(function fooFn() {
console.log("print Foo!");
}, 3000);
fetchData();
}
printFoo();
function fetchData() {
const p = new Promise((res, rej) => {
res("fetch done");
});
p.then((res) => console.log(res));
}
</script>当 js 引擎加载这个 script 脚本的时候,首先会立刻执行 const foo = 'foo' 这行同步代码。接着执行printFoo函数调用,调用 printFoo 函数,会将函数 push 到call-stack中。在printFoo()函数体内,js 又执行了setTimeout这个 api,并将其回调函数fooFn()推入到task中,这个fooFn会在三秒后被执行(不一定是三秒,如果有任务长期在线程中执行大量计算导致线程无法执行其他任务,那么这个时间会持续很久)。
将其回调函数fooFn()推入到task后,接着立即执行fetchData()函数,会将fetchData()推入到call-stack中。在fetchData函数体内,立即将new promise内的匿名函数推入到call-stack中,并将 promise 实例复制给常量p.
接着并调用then将回调函数放入microTask-queue中。
现在整个事件循环的可视化图如下所示
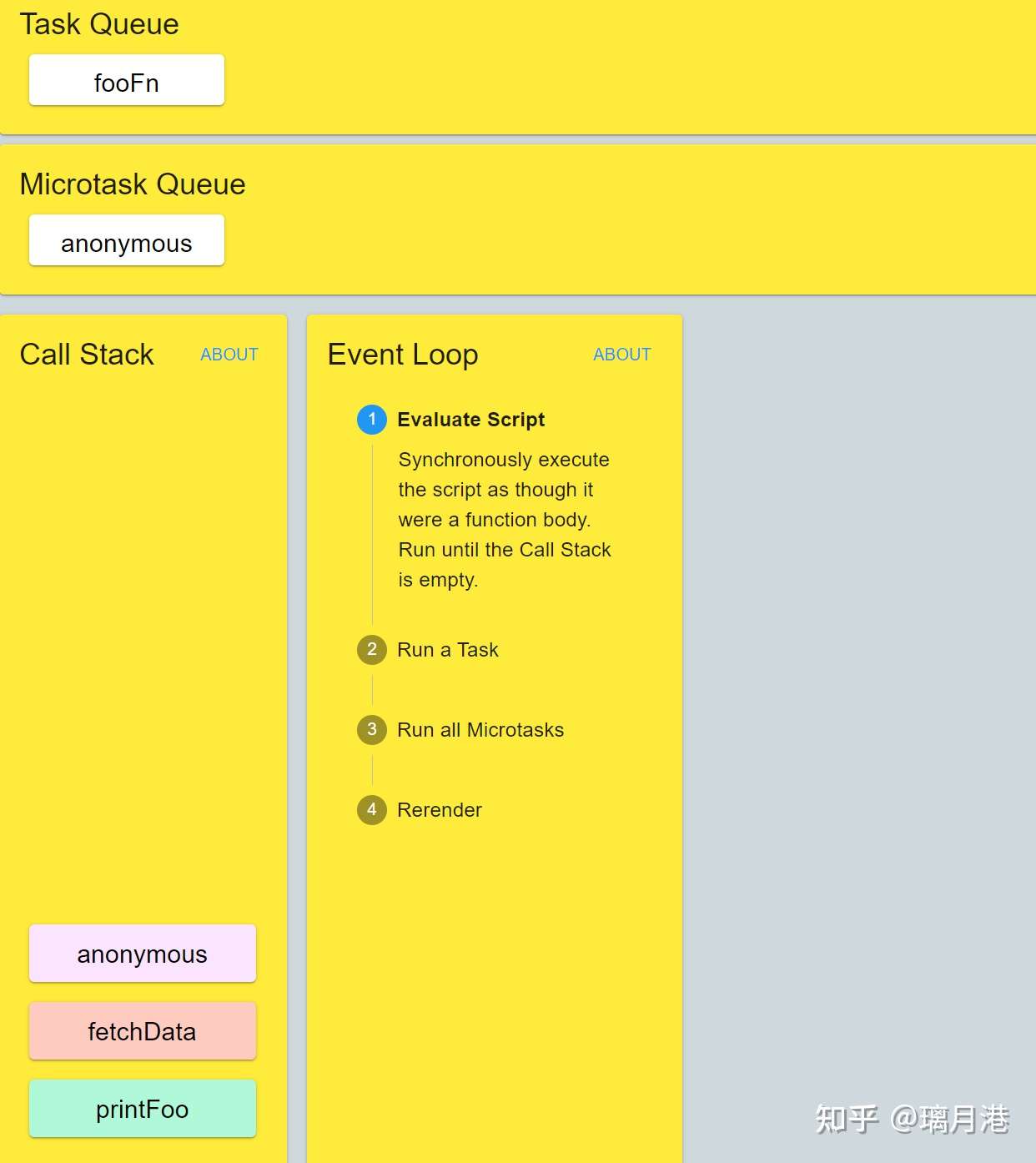
根据上面的预先说的三点概念,processing-model会从call-stack执行完所有的同步任务后,也就是执行完这三个函数后,此时没有任何同步的任务了。接着从Microtask Queue取出p.then中的匿名函数放入到call-stack中执行完毕,此刻微任务队列为空, 开始绘制一次界面。
本次event-loop就此结束。 但是在Task Queue中还有一个fooFn()并未执行。接下来重复上述步骤,开始取出Task Queue中的最近的一个的task并放入到call-stack中执行。一直重复.....
总结
- task-queue 是存放的是一组任务的集合,task-queue的数据结构并不是队列而是Set,task总是会grab第一个可以runable的任务放入到call-stack中运行。
- microTask-queue 是存放一组微任务的队列,具有FIFO的特点,processing-model会不断地从microTask-queue取出一个个的microTask push 到call-stack执行,重复此步骤直到MicroTask Queue为空。
- 当task内的所有的microTask执行完毕后,浏览器会渲染一次UI。